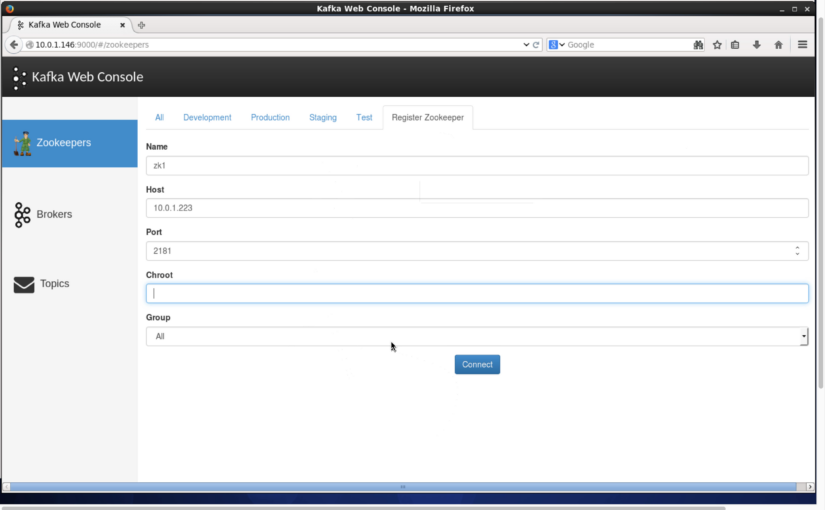
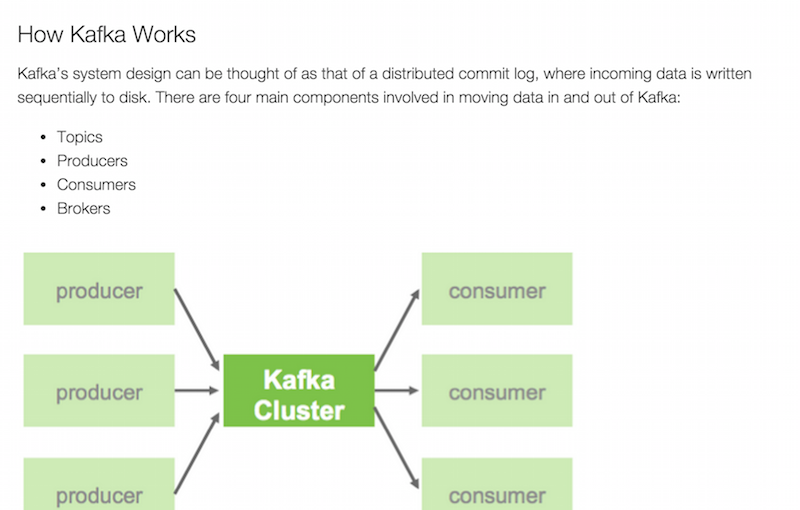
[UPDATE: Check out the Kafka Web Console that allows you to manage topics and see traffic going through your topics – all in a browser!]
When you’re pushing data into a Kafka topic, it’s always helpful to monitor the traffic using a simple Kafka consumer script. Here’s a simple script I’ve been using that subscribes to a given topic and outputs the results. It depends on the kafka-python module and takes a single argument for the topic name. Modify the script to point to the right server IP.
from kafka import KafkaClient, SimpleConsumer
from sys import argv
kafka = KafkaClient("10.0.1.100:6667")
consumer = SimpleConsumer(kafka, "my-group", argv[1])
consumer.max_buffer_size=0
consumer.seek(0,2)
for message in consumer:
print("OFFSET: "+str(message[0])+"\t MSG: "+str(message[1][3]))
Max Buffer Size
There are two lines I wanted to focus on in particular. The first is the “max_buffer_size” setting:
consumer.max_buffer_size=0
When subscribing to a topic with a high level of messages that have not been received before, the consumer/client can max out and fail. Setting an infinite buffer size (zero) allows it to take everything that is available.
If you kill and restart the script it will continue where it last left off, at the last offset that was received. This is pretty cool but in some environments it has some trouble, so I changed the default by adding another line.
Offset Out of Range Error
As I regularly kill the servers running Kafka and the producers feeding it (yes, just for fun), things sometimes go a bit crazy, not entirely sure why but I got the error:
kafka.common.OffsetOutOfRangeError: FetchResponse(topic='my_messages', partition=0, error=1, highwaterMark=-1, messages=)
To fix it I added the “seek” setting:
consumer.seek(0,2)
If you set it to (0,0) it will restart scanning from the first message. Setting it to (0,2) allows it to start from the most recent offset – so letting you tap back into the stream at the latest moment.
Removing this line forces it back to the context mentioned earlier, where it will pick up from the last message it previously received. But if/when that gets broke, then you’ll want to have a line like this to save the day.
For more about Kafka on Hadoop – see Hortonworks excellent overview page from which the screenshot above is taken.